A new tool that improves Claude's complex problem-solving performance
一种提升 Claude 复杂问题解决能力的新工具
Extended thinking capabilities have improved since its initial release, such that we recommend using that feature instead of a dedicated think tool in most cases. Extended thinking provides similar benefits—giving Claude space to reason through complex problems—with better integration and performance. See our extended thinking documentation for implementation details.
自首次发布以来,Claude 的扩展思考(Extended thinking)能力已显著增强,因此在大多数情况下,我们建议直接使用该功能,而非专门实现一个“think”工具。扩展思考提供了类似的优势——为 Claude 留出空间以推理复杂问题——同时具备更优的集成性和性能表现。具体实现细节请参阅我们的扩展思考文档。
As we continue to enhance Claude's complex problem-solving abilities, we've discovered a particularly effective approach: a "think" tool that creates dedicated space for structured thinking during complex tasks.
在持续提升 Claude 复杂问题解决能力的过程中,我们发现了一种尤为有效的方法:引入一个“think”工具,在执行复杂任务时为其创建专门用于结构化思考的空间。
This simple yet powerful technique—which, as we’ll explain below, is different from Claude’s new “extended thinking” capability (see here for extended thinking implementation details)—has resulted in remarkable improvements in Claude's agentic tool use ability. This includes following policies, making consistent decisions, and handling multi-step problems, all with minimal implementation overhead.
这一简单而强大的技术——如我们下文所述,它与 Claude 最新推出的“扩展思考”能力有所不同(扩展思考的实现细节请参见此处)——显著提升了 Claude 在智能体工具使用方面的能力。这包括遵循策略、做出一致决策以及处理多步骤问题,且几乎无需额外的实现成本。
In this post, we'll explore how to implement the “think” tool on different applications, sharing practical guidance for developers based on verified benchmark results.
在本文中,我们将探讨如何在不同应用场景中实现“think”工具,并基于经过验证的基准测试结果,为开发者提供实用的实施指导。
What is the "think" tool?(什么是“think”工具?)
With the "think" tool, we're giving Claude the ability to include an additional thinking step—complete with its own designated space—as part of getting to its final answer.
通过“think”工具,我们赋予 Claude 在得出最终答案的过程中插入一个额外思考步骤的能力——该步骤拥有自己专属的思考空间。
While it sounds similar to extended thinking, it's a different concept. Extended thinking is all about what Claude does before it starts generating a response. With extended thinking, Claude deeply considers and iterates on its plan before taking action. The "think" tool is for Claude, once it starts generating a response, to add a step to stop and think about whether it has all the information it needs to move forward. This is particularly helpful when performing long chains of tool calls or in long multi-step conversations with the user.
尽管这听起来与扩展思考(extended thinking)类似,但两者概念不同。扩展思考关注的是 Claude 在开始生成响应之前所进行的深度规划:它会反复推敲并优化自己的行动计划,然后再采取行动。而“think”工具则用于 Claude 已经开始生成响应之后,主动插入一个暂停点,用以判断当前是否已掌握继续推进所需的全部信息。这一机制在执行长链条的工具调用或与用户进行多轮复杂对话时尤为有用。
This makes the “think” tool more suitable for cases where Claude does not have all the information needed to formulate its response from the user query alone, and where it needs to process external information (e.g. information in tool call results). The reasoning Claude performs with the “think” tool is less comprehensive than what can be obtained with extended thinking, and is more focused on new information that the model discovers.
因此,“think”工具更适合以下场景:Claude 无法仅凭用户查询就获取制定响应所需的全部信息,而必须处理外部信息(例如工具调用返回的结果)。“think”工具所支持的推理不如扩展思考那样全面,而是更聚焦于模型在交互过程中新发现的信息。
We recommend using extended thinking for simpler tool use scenarios like non-sequential tool calls or straightforward instruction following. Extended thinking is also useful for use cases, like coding, math, and physics, when you don’t need Claude to call tools. The “think” tool is better suited for when Claude needs to call complex tools, analyze tool outputs carefully in long chains of tool calls, navigate policy-heavy environments with detailed guidelines, or make sequential decisions where each step builds on previous ones and mistakes are costly.
我们建议在较简单的工具使用场景中采用扩展思考,例如非顺序性的工具调用或直接遵循指令的任务。此外,在无需调用工具的场景(如编程、数学和物理问题求解)中,扩展思考同样非常有效。相比之下,“think”工具更适用于 Claude 需要调用复杂工具、在长链条工具调用中仔细分析工具输出、在政策密集且指南详尽的环境中导航,或进行高成本错误敏感的序列化决策(每一步都依赖前序结果)等复杂情境。
Here's a sample implementation using the standard tool specification format that comes from τ-Bench:
以下是一个基于 τ-Bench 提供的标准工具规范格式的示例实现:
{
"name": "think",
"description": "Use the tool to think about something. It will not obtain new information or change the database, but just append the thought to the log. Use it when complex reasoning or some cache memory is needed.",
"input_schema": {
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "A thought to think about."
}
},
"required": ["thought"]
}
}Performance on τ-Bench(在 τ-Bench 上的性能表现)
We evaluated the "think" tool using τ-bench (tau-bench), a comprehensive benchmark designed to test a model’s ability to use tools in realistic customer service scenarios, where the "think" tool is part of the evaluation’s standard environment.
我们使用 τ-Bench(tau-bench)对“think”工具进行了评估。τ-Bench 是一个综合性基准测试,旨在检验模型在真实客户服务场景中使用工具的能力,其中“think”工具已被纳入评估的标准环境。
τ-bench evaluates Claude's ability to:
Navigate realistic conversations with simulated users
Follow complex customer service agent policy guidelines consistently
Use a variety of tools to access and manipulate the environment database
τ-Bench 评估 Claude 在以下方面的能力:
与模拟用户进行逼真的对话交互
始终如一地遵循复杂的客户服务代理政策指南
使用多种工具访问并操作环境数据库
The primary evaluation metric used in τ-bench is pass^k, which measures the probability that all k independent task trials are successful for a given task, averaged across all tasks. Unlike the pass@k metric that is common for other LLM evaluations (which measures if at least one of k trials succeeds), pass^k evaluates consistency and reliability—critical qualities for customer service applications where consistent adherence to policies is essential.
τ-Bench 采用的主要评估指标是 pass^k,该指标衡量的是:对于给定任务,所有 k 次独立尝试均成功的概率,并在所有任务上取平均值。这与常用于其他大语言模型评估的 pass@k 指标不同(后者仅衡量 k 次尝试中至少有一次成功即可)。pass^k 强调一致性和可靠性——这在客户服务应用中至关重要,因为严格、稳定地遵守政策是基本要求。
Performance Analysis(性能分析)
Our evaluation compared several different configurations:
Baseline (no "think" tool, no extended thinking mode)
Extended thinking mode alone
"Think" tool alone
"Think" tool with optimized prompt (for airline domain)
我们的评估对比了以下几种不同配置:
基线(无“think”工具,未启用扩展思考模式)
仅启用扩展思考模式
仅使用“think”工具
使用针对航空领域优化提示的“think”工具
The results showed dramatic improvements when Claude 3.7 effectively used the "think" tool in both the “airline” and “retail” customer service domains of the benchmark:
Airline domain: The "think" tool with an optimized prompt achieved 0.570 on the pass^1 metric, compared to just 0.370 for the baseline—a 54% relative improvement;
Retail domain: The "think" tool alone achieves 0.812, compared to 0.783 for the baseline.
结果显示,当 Claude 3.7 在该基准测试的“航空”和“零售”两个客户服务领域有效运用“think”工具时,性能显著提升:
航空领域:采用优化提示的“think”工具在 pass^1 指标上达到 0.570,而基线仅为 0.370,相对提升达 54%;
零售领域:仅使用“think”工具即达到 0.812,而基线为 0.783。
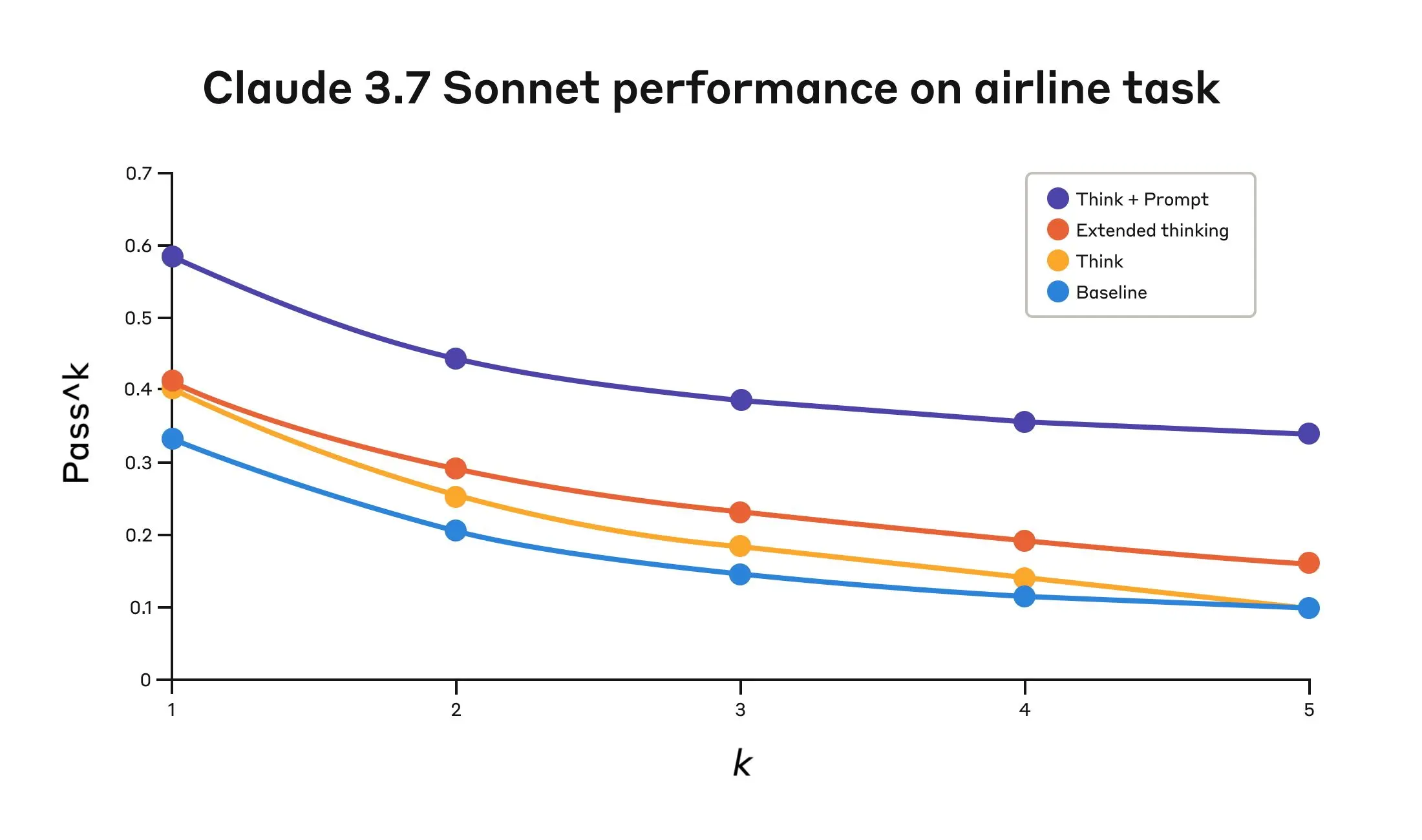
Claude 3.7 Sonnet's performance on the "airline" domain of the Tau-Bench eval under four different configurations.
Claude 3.7 Sonnet 在 Tau-Bench 评估中“航空”领域四种不同配置下的性能表现。
Claude 3.7 Sonnet's performance on the "Airline" domain of the Tau-Bench eval
Claude 3.7 Sonnet 在 Tau-Bench 评估中“Airline领域的性能表现。
Configuration
k=1
k=2
k=3
k=4
k=5
"Think" + Prompt
0.584
0.444
0.384
0.356
0.340
"Think"
0.404
0.254
0.186
0.140
0.100
Extended thinking
0.412
0.290
0.232
0.192
0.160
Baseline
0.332
0.206
0.148
0.116
0.100
Evaluation results across four different configurations. Scores are proportions.
四种不同配置下的评估结果。分数以比例形式呈现。
The best performance in the airline domain was achieved by pairing the “think” tool with an optimized prompt that gives examples of the type of reasoning approaches to use when analyzing customer requests. Below is an example of the optimized prompt:
在航空领域,最佳性能是通过将“think”工具与一个经过优化的提示词结合实现的,该提示词提供了在分析客户请求时应采用的推理方法示例。以下是一个优化提示词的示例:
## Using the think tool Before taking any action or responding to the user after receiving tool results, use the think tool as a scratchpad to: - List the specific rules that apply to the current request - Check if all required information is collected - Verify that the planned action complies with all policies - Iterate over tool results for correctness Here are some examples of what to iterate over inside the think tool: <think_tool_example_1> User wants to cancel flight ABC123 - Need to verify: user ID, reservation ID, reason - Check cancellation rules: * Is it within 24h of booking? * If not, check ticket class and insurance - Verify no segments flown or are in the past - Plan: collect missing info, verify rules, get confirmation </think_tool_example_1> <think_tool_example_2> User wants to book 3 tickets to NYC with 2 checked bags each - Need user ID to check: * Membership tier for baggage allowance * Which payments methods exist in profile - Baggage calculation: * Economy class × 3 passengers * If regular member: 1 free bag each → 3 extra bags = $150 * If silver member: 2 free bags each → 0 extra bags = $0 * If gold member: 3 free bags each → 0 extra bags = $0 - Payment rules to verify: * Max 1 travel certificate, 1 credit card, 3 gift cards * All payment methods must be in profile * Travel certificate remainder goes to waste - Plan: 1. Get user ID 2. Verify membership level for bag fees 3. Check which payment methods in profile and if their combination is allowed 4. Calculate total: ticket price + any bag fees 5. Get explicit confirmation for booking </think_tool_example_2>
What's particularly interesting is how the different approaches compared. Using the “think” tool with the optimized prompt achieved significantly better results over extended thinking mode (which showed similar performance to the unprompted “think” tool). Using the "think" tool alone (without prompting) improved performance over baseline, but still fell short of the optimized approach.
尤其值得关注的是不同方法之间的对比结果。“think”工具配合优化后的提示词显著优于扩展思考模式(后者的表现与未加提示的“think”工具相近)。仅使用“think”工具(无额外提示)虽已优于基线水平,但仍不及经过提示优化的方案。
The combination of the "think" tool with optimized prompting delivered the strongest performance by a significant margin, likely due to the high complexity of the airline policy part of the benchmark, where the model benefitted the most from being given examples of how to “think.”
“think”工具与优化提示相结合的方式以显著优势取得了最佳性能,这很可能是因为该基准测试中航空政策部分复杂度极高,模型在获得“如何思考”的具体示例后受益最大。
In the retail domain, we also tested various configurations to understand the specific impact of each approach
在零售领域,我们也测试了多种配置,以深入理解每种方法所带来的具体影响。
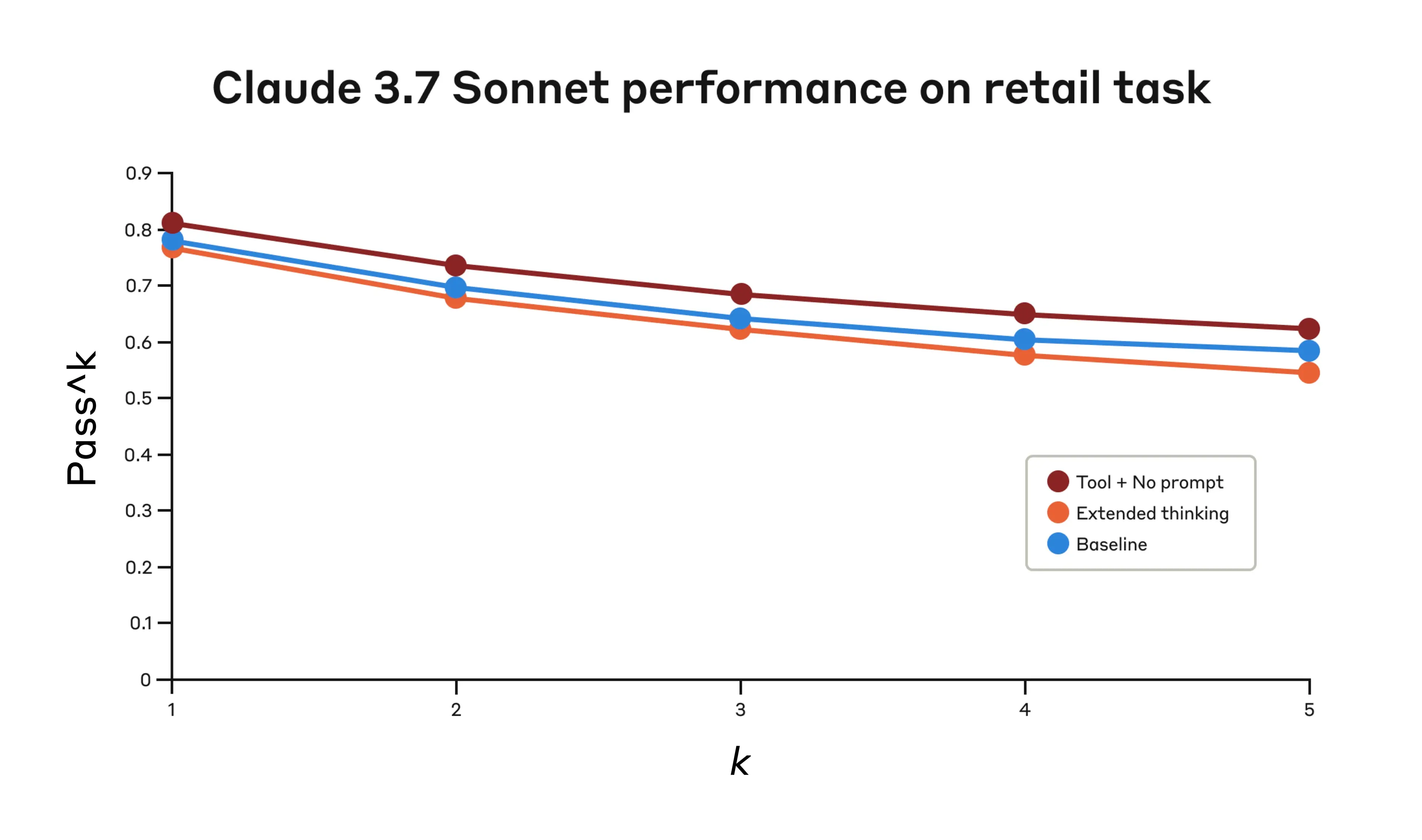
Performance of Claude 3.7 Sonnet on the "retail" domain of the Tau-Bench eval under three different configurations.
Claude 3.7 Sonnet 在 Tau-Bench 评估中“零售”领域三种不同配置下的性能表现。
Claude 3.7 Sonnet's performance on the "Retail" domain of the Tau-Bench eval
Claude 3.7 Sonnet 在 Tau-Bench 评估中“零售”领域的性能表现。
Configuration
k=1
k=2
k=3
k=4
k=5
"Think" + no prompt
0.812
0.735
0.685
0.650
0.626
Extended thinking
0.770
0.681
0.623
0.581
0.548
Baseline
0.783
0.695
0.643
0.607
0.583
Evaluation results across three different configurations. Scores are proportions.
三种不同配置下的评估结果。分数以比例形式呈现。
The "think" tool achieved the highest pass^1 score of 0.812 even without additional prompting. The retail policy is noticeably easier to navigate compared to the airline domain, and Claude was able to improve just by having a space to think without further guidance.
即使没有额外的提示,“think”工具也取得了最高的 pass^1 分数 0.812。与航空领域相比,零售领域的政策明显更易于处理,Claude 仅需拥有一个独立的思考空间,无需进一步指导,便能实现性能提升。
Key Insights from τ-Bench Analysis(τ-Bench 分析的关键洞察)
Our detailed analysis revealed several patterns that can help you implement the "think" tool effectively:
Prompting matters significantly on difficult domains. Simply making the "think" tool available might improve performance somewhat, but pairing it with optimized prompting yielded dramatically better results for difficult domains. However, easier domains may benefit from simply having access to “think.”
Improved consistency across trials. The improvements from using “think” were maintained for pass^k up to k=5, indicating that the tool helped Claude handle edge cases and unusual scenarios more effectively.
我们的详细分析揭示了若干有助于有效实施“think”工具的规律:
在复杂领域中,提示词至关重要。仅仅提供“think”工具可能带来一定程度的性能提升,但在复杂领域中,将其与优化后的提示词结合使用可显著提升效果。相比之下,在较简单的领域中,仅提供“think”工具本身就可能带来收益。
跨多次试验的一致性得到改善。使用“think”工具带来的性能提升在 pass^k(k 最高至 5)指标上均得以维持,表明该工具帮助 Claude 更有效地应对边缘案例和异常场景。
Performance on SWE-Bench(在 SWE-Bench 上的表现)
A similar “think” tool was added to our SWE-bench setup when evaluating Claude 3.7 Sonnet, contributing to the achieved state-of-the-art score of 0.623. The adapted “think” tool definition is given below:
在评估 Claude 3.7 Sonnet 时,我们在 SWE-Bench 设置中也引入了类似的“think”工具,助力其取得了 0.623 的业界领先分数。以下是适配后的“think”工具定义:
{
"name": "think",
"description": "Use the tool to think about something. It will not obtain new information or make any changes to the repository, but just log the thought. Use it when complex reasoning or brainstorming is needed. For example, if you explore the repo and discover the source of a bug, call this tool to brainstorm several unique ways of fixing the bug, and assess which change(s) are likely to be simplest and most effective. Alternatively, if you receive some test results, call this tool to brainstorm ways to fix the failing tests.",
"input_schema": {
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "Your thoughts."
}
},
"required": ["thought"]
}
}Our experiments (n=30 samples with "think" tool, n=144 samples without) showed the isolated effects of including this tool improved performance by 1.6% on average (Welch's t-test: t(38.89) = 6.71, p < .001, d = 1.47).
我们的实验(使用“think”工具的样本 n=30,未使用的样本 n=144)表明,单独引入该工具平均可将性能提升 1.6%(Welch’s t 检验:t(38.89) = 6.71,p < .001,Cohen’s d = 1.47)。
When to use the "think" tool(何时使用“think”工具)
Based on these evaluation results, we've identified specific scenarios where Claude benefits most from the "think" tool:
Tool output analysis. When Claude needs to carefully process the output of previous tool calls before acting and might need to backtrack in its approach;
Policy-heavy environments. When Claude needs to follow detailed guidelines and verify compliance; and
Sequential decision making. When each action builds on previous ones and mistakes are costly (often found in multi-step domains).
基于上述评估结果,我们识别出 Claude 最能从“think”工具中获益的特定场景:
工具输出分析:当 Claude 需要在采取下一步行动前仔细处理先前工具调用的输出,并可能需要回溯调整其策略时;
政策密集型环境:当 Claude 需要遵循详细指南并验证合规性时;
序列化决策:当每个操作都依赖于前序步骤,且错误代价高昂时(常见于多步骤任务领域)。
Implementation best practices(实施最佳实践)
To get the most out of the "think" tool with Claude, we recommend the following implementation practices based on our τ-bench experiments.
1. Strategic prompting with domain-specific examples(为在 Claude 中最大化“think”工具的效果,我们根据 τ-Bench 实验总结了以下实施建议:
)
The most effective approach is to provide clear instructions on when and how to use the "think" tool, such as the one used for the τ-bench airline domain. Providing examples tailored to your specific use case significantly improves how effectively the model uses the "think" tool:
The level of detail expected in the reasoning process;
How to break down complex instructions into actionable steps;
Decision trees for handling common scenarios; and
How to check if all necessary information has been collected.
最有效的方法是提供清晰的指令,说明何时以及如何使用“think”工具——例如 τ-Bench 航空领域所采用的方式。针对具体应用场景定制示例,能显著提升模型使用该工具的有效性,包括:
推理过程中应达到的细节程度;
如何将复杂指令拆解为可执行的步骤;
处理常见场景的决策树;
如何检查是否已收集所有必要信息。
2. Place complex guidance in the system prompt(将复杂指引置于系统提示中)
We found that, when they were long and/or complex, including instructions about the "think" tool in the system prompt was more effective than placing them in the tool description itself. This approach provides broader context and helps the model better integrate the thinking process into its overall behavior.
我们发现,当关于“think”工具的说明较长或较复杂时,将其放在系统提示(system prompt)中比放在工具描述本身更有效。这种方式提供了更广泛的上下文,有助于模型将思考过程更好地融入整体行为中。
When not to use the "think" tool(何时不应使用“think”工具)
Whereas the “think” tool can offer substantial improvements, it is not applicable to all tool use use cases, and does come at the cost of increased prompt length and output tokens. Specifically, we have found the “think” tool does not offer any improvements in the following use cases:
Non-sequential tool calls. If Claude only needs to make a single tool call or multiple parallel calls to complete a task, there is unlikely to be any improvements from adding in “think.”
Simple instruction following. When there are not many constraints to which Claude needs to adhere, and its default behaviour is good enough, there are unlikely to be gains from additional “think”-ing.
尽管“think”工具能带来显著提升,但它并不适用于所有工具使用场景,且会增加提示长度和输出 token 的消耗。具体而言,我们在以下场景中未观察到任何性能增益:
非序列化工具调用:如果 Claude 只需执行单次工具调用,或并行执行多个独立调用即可完成任务,则添加“think”工具不太可能带来改进。
简单指令遵循:当任务约束较少,且 Claude 的默认行为已足够可靠时,额外的“思考”通常不会带来收益。
Getting started(快速上手)
The "think" tool is a straightforward addition to your Claude implementation that can yield meaningful improvements in just a few steps:
Test with agentic tool use scenarios. Start with challenging use cases—ones where Claude currently struggles with policy compliance or complex reasoning in long tool call chains.
Add the tool definition. Implement a "think" tool customized to your domain. It requires minimal code but enables more structured reasoning. Also consider including instructions on when and how to use the tool, with examples relevant to your domain to the system prompt.
Monitor and refine. Watch how Claude uses the tool in practice, and adjust your prompts to encourage more effective thinking patterns.
“think”工具是一种简单易行的 Claude 功能扩展,仅需几个步骤即可带来实质性改进:
在智能体工具使用场景中测试:从具有挑战性的用例入手——例如 Claude 当前在政策合规或多步骤工具调用链中推理困难的任务。
添加工具定义:实现一个针对你所在领域的“think”工具。它所需代码极少,却能支持更结构化的推理。同时,考虑在系统提示中加入关于何时及如何使用该工具的说明,并提供与你领域相关的示例。
监控并优化:观察 Claude 在实际中如何使用该工具,并调整提示以鼓励更有效的思考模式。
The best part is that adding this tool has minimal downside in terms of performance outcomes. It doesn't change external behavior unless Claude decides to use it, and doesn't interfere with your existing tools or workflows.
最值得称道的是,添加此工具在性能结果方面几乎没有任何负面影响。除非 Claude 主动选择使用它,否则不会改变外部行为,也不会干扰你现有的工具或工作流。
Conclusion(结论)
Our research has demonstrated that the "think" tool can significantly enhance Claude 3.7 Sonnet's performance1 on complex tasks requiring policy adherence and reasoning in long chains of tool calls. “Think” is not a one-size-fits-all solution, but it offers substantial benefits for the correct use cases, all with minimal implementation complexity.
我们的研究表明,“think”工具能显著提升 Claude 3.7 Sonnet 在需要政策遵循和长链条工具调用中进行复杂推理的任务上的表现¹。“think”并非万能方案,但在适用场景下能带来可观收益,且实现复杂度极低。
We look forward to seeing how you'll use the "think" tool to build more capable, reliable, and transparent AI systems with Claude.
我们期待看到你如何利用“think”工具,基于 Claude 构建更强大、可靠且透明的 AI 系统。
1. While our τ-Bench results focused on the improvement of Claude 3.7 Sonnet with the “think” tool, our experiments show Claude 3.5 Sonnet (New) is also able to achieve performance gains with the same configuration as 3.7 Sonnet, indicating that this improvement generalizes to other Claude models as well.
¹ 尽管我们的 τ-Bench 结果聚焦于 Claude 3.7 Sonnet 使用“think”工具后的改进,但实验表明,Claude 3.5 Sonnet(新版)在相同配置下同样能获得性能提升,说明这一改进可推广至其他 Claude 模型。

发表评论 取消回复