Agents are only as effective as the tools we give them. We share how to write high-quality tools and evaluations, and how you can boost performance by using Claude to optimize its tools for itself.
智能体的效果完全取决于我们赋予它们的工具。本文将分享如何编写高质量的工具和评估方法,并介绍如何利用 Claude 自行优化其工具,从而提升整体性能。
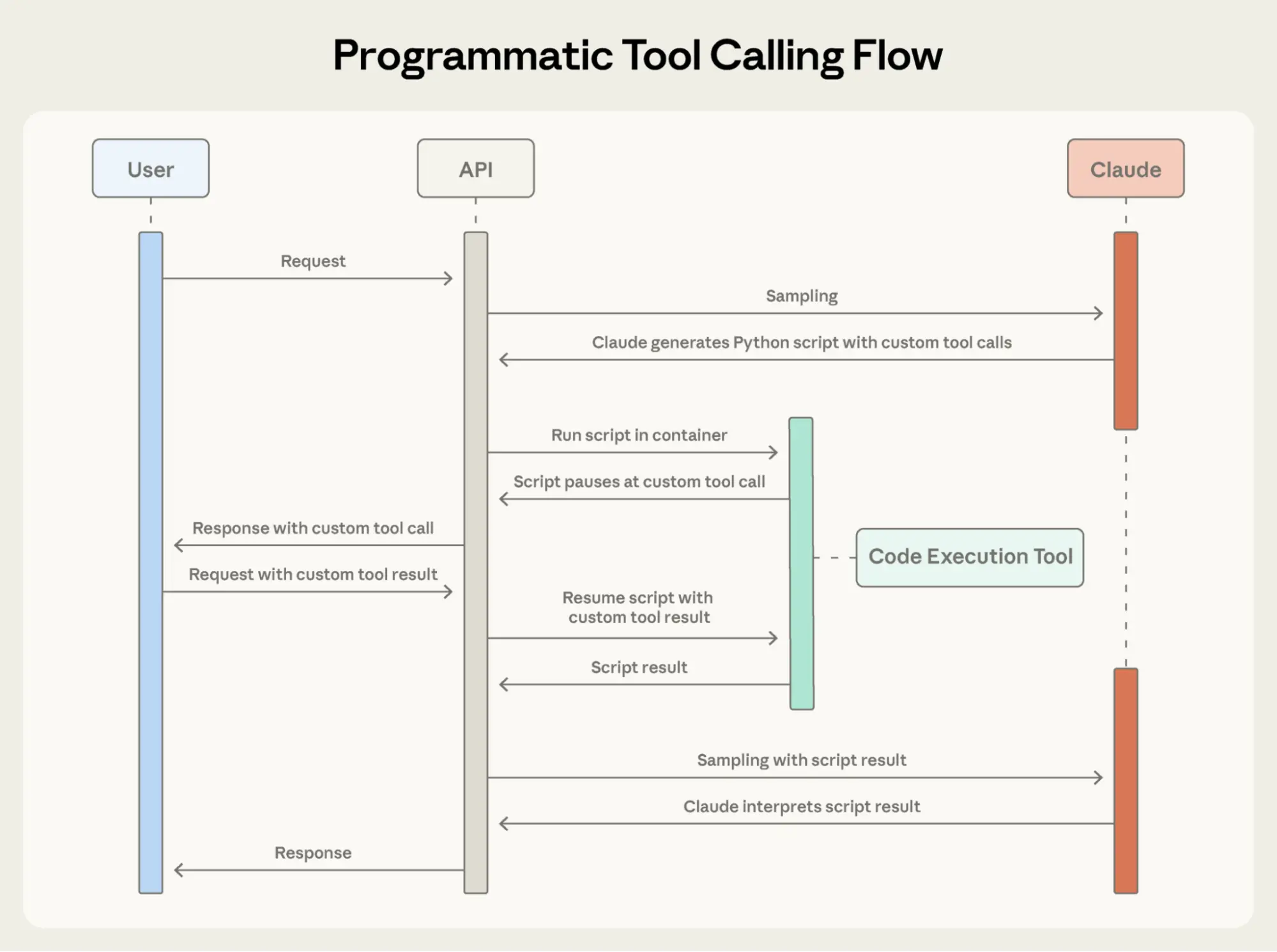
The Model Context Protocol (MCP) can empower LLM agents with potentially hundreds of tools to solve real-world tasks. But how do we make those tools maximally effective?
模型上下文协议(Model Context Protocol,MCP)可为大语言模型(LLM)智能体配备多达数百种工具,以应对现实世界中的任务。但我们要如何让这些工具发挥最大效用呢?
In this post, we describe our most effective techniques for improving performance in a variety of agentic AI systems1.
在本文中,我们将介绍一系列经实践验证、能有效提升各类智能体 AI 系统性能的技术。
We begin by covering how you can:
Build and test prototypes of your tools
Create and run comprehensive evaluations of your tools with agents
Collaborate with agents like Claude Code to automatically increase the performance of your tools
首先,我们将说明你可以如何:
构建并测试你的工具原型
利用智能体对工具开展全面的评估与测试
与 Claude Code 等智能体协作,自动提升工具的性能
We conclude with key principles for writing high-quality tools we’ve identified along the way:
Choosing the right tools to implement (and not to implement)
Namespacing tools to define clear boundaries in functionality
Returning meaningful context from tools back to agents
Optimizing tool responses for token efficiency
Prompt-engineering tool descriptions and specs
最后,我们将总结在实践中提炼出的编写高质量工具的核心原则:
合理选择要实现(以及不实现)的工具
通过命名空间(namespacing)明确界定工具的功能边界
让工具向智能体返回有意义的上下文信息
优化工具响应内容,提升 token 使用效率
对工具的描述和规范进行提示工程(prompt engineering)优化
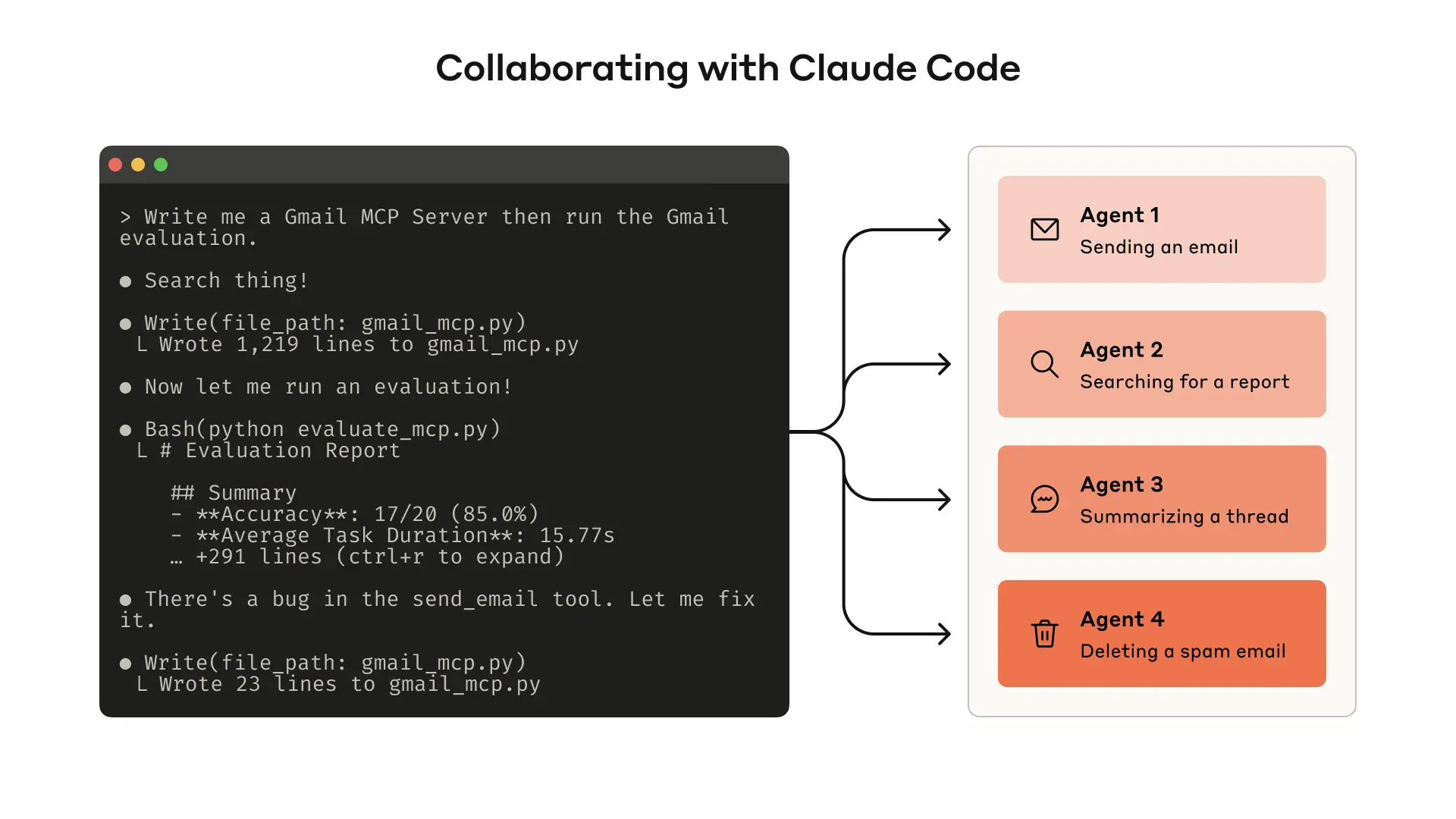
Building an evaluation allows you to systematically measure the performance of your tools. You can use Claude Code to automatically optimize your tools against this evaluation.
建立评估机制能够让你系统地测量工具的性能。你可以使用 Claude Code 自动根据这一评估来优化你的工具。 什么是工具?
What is a tool?(什么是工具?)
In computing, deterministic systems produce the same output every time given identical inputs, while non-deterministic systems—like agents—can generate varied responses even with the same starting conditions.
在计算领域,确定性系统在给定相同输入的情况下每次都会产生相同的输出,而非确定性系统——如智能体——即使在相同的初始条件下也可能生成不同的响应。
When we traditionally write software, we’re establishing a contract between deterministic systems. For instance, a function call like getWeather(“NYC”) will always fetch the weather in New York City in the exact same manner every time it is called.
当我们传统上编写软件时,我们是在确定性系统之间建立一种契约。例如,像 getWeather("NYC") 这样的函数调用每次被调用时都会以完全相同的方式获取纽约市的天气信息。
Tools are a new kind of software which reflects a contract between deterministic systems and non-deterministic agents. When a user asks "Should I bring an umbrella today?,” an agent might call the weather tool, answer from general knowledge, or even ask a clarifying question about location first. Occasionally, an agent might hallucinate or even fail to grasp how to use a tool.
工具是一种新型软件,它反映了确定性系统与非确定性智能体之间的契约。当用户询问“我今天应该带伞吗?”时,智能体可能会调用天气工具,从一般知识中回答,或者甚至首先问一个关于地点的澄清问题。有时,智能体可能会产生幻觉或甚至无法理解如何使用某个工具。
This means fundamentally rethinking our approach when writing software for agents: instead of writing tools and MCP servers the way we’d write functions and APIs for other developers or systems, we need to design them for agents.
这意味着在为智能体编写软件时,我们需要从根本上重新思考我们的方法:不是按照为其他开发者或系统编写函数和API的方式来编写工具和MCP服务器,而是需要为智能体设计它们。
Our goal is to increase the surface area over which agents can be effective in solving a wide range of tasks by using tools to pursue a variety of successful strategies. Fortunately, in our experience, the tools that are most “ergonomic” for agents also end up being surprisingly intuitive to grasp as humans.
我们的目标是通过使用工具追求各种成功的策略,扩大智能体在解决广泛任务中的有效范围。幸运的是,在我们的经验中,对于智能体来说最“易用”的工具最终也出乎意料地易于人类理解。
How to write tools(如何编写工具)
In this section, we describe how you can collaborate with agents both to write and to improve the tools you give them. Start by standing up a quick prototype of your tools and testing them locally. Next, run a comprehensive evaluation to measure subsequent changes. Working alongside agents, you can repeat the process of evaluating and improving your tools until your agents achieve strong performance on real-world tasks.
在本节中,我们将描述你如何与智能体合作,既编写又改进你提供给他们的工具。首先快速搭建工具原型并在本地进行测试。接下来,运行全面评估以测量后续的变化。与智能体一起工作,你可以重复评估和改进工具的过程,直到智能体在现实世界的任务中实现强大的性能。
Building a prototype(构建原型)
It can be difficult to anticipate which tools agents will find ergonomic and which tools they won’t without getting hands-on yourself. Start by standing up a quick prototype of your tools. If you’re using Claude Code to write your tools (potentially in one-shot), it helps to give Claude documentation for any software libraries, APIs, or SDKs (including potentially the MCP SDK) your tools will rely on. LLM-friendly documentation can commonly be found in flat llms.txt files on official documentation sites (here’s our API’s).
在没有亲自动手之前,很难预测哪些工具对智能体来说是符合人体工程学的,哪些则不是。首先快速搭建你的工具原型。如果你正在使用Claude Code来编写你的工具(可能一次性完成),最好给Claude提供任何你的工具将依赖的软件库、API或SDK(包括可能的MCP SDK)的文档。LLM友好的文档通常可以在官方文档网站上的平面llms.txt文件中找到(这是我们的API的链接)
Wrapping your tools in a local MCP server or Desktop extension (DXT) will allow you to connect and test your tools in Claude Code or the Claude Desktop app.
将你的工具包裹在一个本地的MCP服务器或桌面扩展(DXT)中,可以让你连接并在Claude Code或Claude桌面应用程序中测试这些工具。
To connect your local MCP server to Claude Code, run claude mcp add <name> <command> [args...].
要将你的本地MCP服务器连接到Claude Code,运行 claude mcp add [args...]。
To connect your local MCP server or DXT to the Claude Desktop app, navigate to Settings > Developer or Settings > Extensions, respectively.
要将你的本地MCP服务器或DXT连接到Claude桌面应用程序,请分别导航至设置>开发者或设置>扩展。
Tools can also be passed directly into Anthropic API calls for programmatic testing.
工具也可以直接传递到Anthropic API调用中进行程序化测试。
Test the tools yourself to identify any rough edges. Collect feedback from your users to build an intuition around the use-cases and prompts you expect your tools to enable.
自己测试工具以识别任何粗糙的边缘。收集用户的反馈来构建关于你期望工具支持的使用场景和提示的直觉。
Running an evaluation(运行评估)
Next, you need to measure how well Claude uses your tools by running an evaluation. Start by generating lots of evaluation tasks, grounded in real world uses. We recommend collaborating with an agent to help analyze your results and determine how to improve your tools. See this process end-to-end in our tool evaluation cookbook.
接下来,你需要通过运行评估来测量Claude使用你的工具的效果。首先,生成大量的基于现实世界使用的评估任务。我们建议与智能体合作帮助分析结果并决定如何改进你的工具。请参阅我们的工具评估指南了解整个过程。
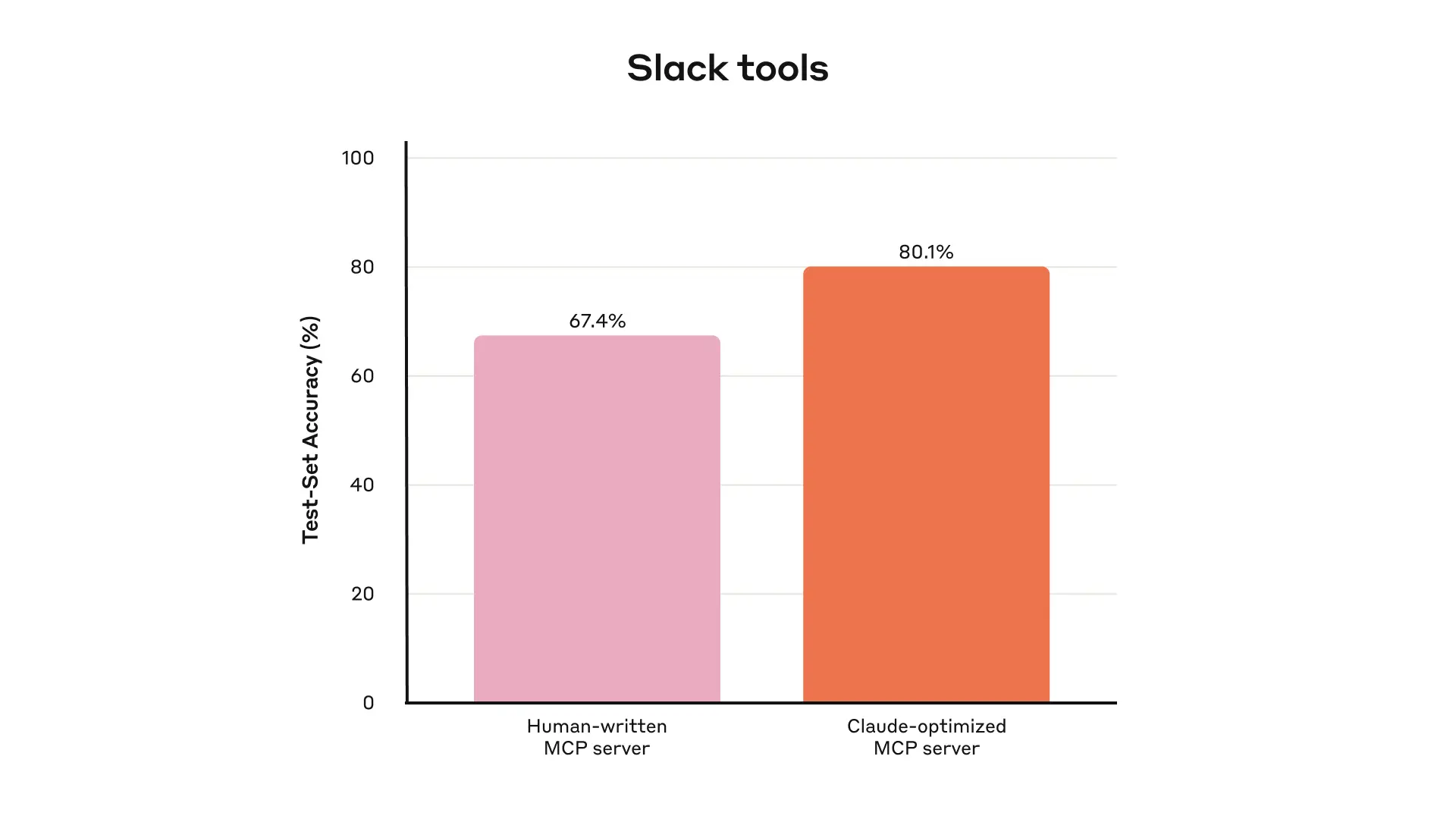
Held-out test set performance of our internal Slack tools
这是我们内部Slack工具保留测试集性能的表现。
Generating evaluation tasks(生成评估任务)
With your early prototype, Claude Code can quickly explore your tools and create dozens of prompt and response pairs. Prompts should be inspired by real-world uses and be based on realistic data sources and services (for example, internal knowledge bases and microservices). We recommend you avoid overly simplistic or superficial “sandbox” environments that don’t stress-test your tools with sufficient complexity. Strong evaluation tasks might require multiple tool calls—potentially dozens.
借助早期原型,Claude Code 可以快速探索你的工具,并生成数十组提示与响应对。这些提示应源于真实世界的使用场景,并基于现实的数据源和服务(例如内部知识库和微服务)。我们建议避免使用过于简单或表面化的“沙盒”环境,因为这类环境无法通过足够的复杂性对你的工具进行充分的压力测试。高质量的评估任务可能需要多次工具调用——有时甚至多达数十次。
Here are some examples of strong tasks:
Schedule a meeting with Jane next week to discuss our latest Acme Corp project. Attach the notes from our last project planning meeting and reserve a conference room.
Customer ID 9182 reported that they were charged three times for a single purchase attempt. Find all relevant log entries and determine if any other customers were affected by the same issue.
Customer Sarah Chen just submitted a cancellation request. Prepare a retention offer. Determine: (1) why they're leaving, (2) what retention offer would be most compelling, and (3) any risk factors we should be aware of before making an offer.
以下是一些高质量任务的示例:
安排下周与 Jane 会面,讨论我们最新的 Acme Corp 项目。附上上次项目规划会议的笔记,并预订一间会议室。
客户 ID 9182 报告称,其单次购买尝试被重复扣款三次。查找所有相关日志条目,并判断是否有其他客户受到相同问题的影响。
客户 Sarah Chen 刚刚提交了取消请求。请准备一份挽留方案。确定:(1) 她离开的原因;(2) 最具说服力的挽留方案;(3) 在提出方案前我们应关注的任何风险因素。
And here are some weaker tasks:
Schedule a meeting with jane@acme.corp next week.
Search the payment logs for purchase_complete and customer_id=9182.
Find the cancellation request by Customer ID 45892.
而以下是一些较弱的任务示例:
安排下周与 jane@acme.corp 会面。
在支付日志中搜索 purchase_complete 和 customer_id=9182。
查找客户 ID 为 45892 的取消请求。
Each evaluation prompt should be paired with a verifiable response or outcome. Your verifier can be as simple as an exact string comparison between ground truth and sampled responses, or as advanced as enlisting Claude to judge the response. Avoid overly strict verifiers that reject correct responses due to spurious differences like formatting, punctuation, or valid alternative phrasings.
每个评估提示都应配有一个可验证的响应或结果。你的验证器可以简单到对标准答案与模型输出进行精确字符串比对,也可以复杂到让 Claude 来评判响应质量。应避免使用过于严苛的验证器,以免因格式、标点或合理替代表述等无关差异而拒绝正确的回答。
For each prompt-response pair, you can optionally also specify the tools you expect an agent to call in solving the task, to measure whether or not agents are successful in grasping each tool’s purpose during evaluation. However, because there might be multiple valid paths to solving tasks correctly, try to avoid overspecifying or overfitting to strategies.
对于每组提示-响应对,你可以选择性地指定你期望智能体在完成任务时调用的工具,以衡量智能体是否在评估过程中准确理解了每个工具的用途。然而,由于完成任务可能存在多种有效路径,应尽量避免过度指定或过度拟合于某一种策略。
Running the evaluation(运行评估)
We recommend running your evaluation programmatically with direct LLM API calls. Use simple agentic loops (while-loops wrapping alternating LLM API and tool calls): one loop for each evaluation task. Each evaluation agent should be given a single task prompt and your tools.
我们建议通过直接调用 LLM API 以程序化方式运行评估。使用简单的智能体循环(即 while 循环,交替调用 LLM API 和工具):每个评估任务对应一个循环。每个评估智能体应仅接收一个任务提示和你的工具集。
In your evaluation agents’ system prompts, we recommend instructing agents to output not just structured response blocks (for verification), but also reasoning and feedback blocks. Instructing agents to output these before tool call and response blocks may increase LLMs’ effective intelligence by triggering chain-of-thought (CoT) behaviors.
在评估智能体的系统提示中,我们建议指示智能体不仅输出结构化的响应块(用于验证),还要输出推理过程和反馈块。要求智能体在工具调用和响应块之前先输出这些内容,可能通过触发思维链(Chain-of-Thought, CoT)行为来提升 LLM 的实际智能表现。
If you’re running your evaluation with Claude, you can turn on interleaved thinking for similar functionality “off-the-shelf”. This will help you probe why agents do or don’t call certain tools and highlight specific areas of improvement in tool descriptions and specs.
如果你使用 Claude 运行评估,可以开启“交错式思考”(interleaved thinking)功能,该功能开箱即用,效果类似。这将帮助你探究智能体为何调用或不调用某些工具,并突出显示工具描述和规范中需要改进的具体方面。
As well as top-level accuracy, we recommend collecting other metrics like the total runtime of individual tool calls and tasks, the total number of tool calls, the total token consumption, and tool errors. Tracking tool calls can help reveal common workflows that agents pursue and offer some opportunities for tools to consolidate.
除了整体准确率外,我们还建议收集其他指标,例如单个工具调用和任务的总运行时间、工具调用总次数、总 token 消耗量以及工具错误数量。追踪工具调用有助于揭示智能体常用的典型工作流,并为工具整合提供优化机会。
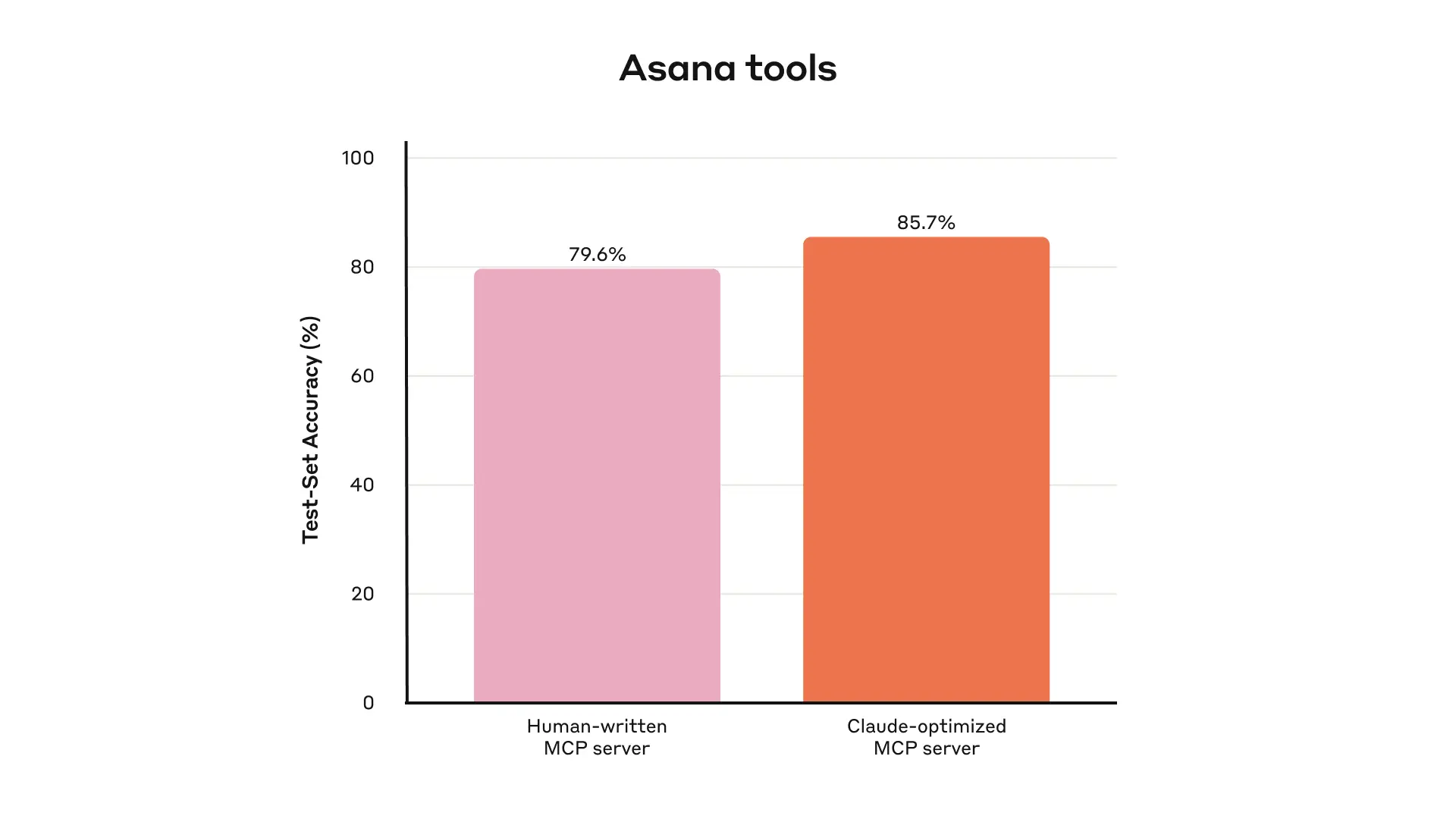
Held-out test set performance of our internal Asana tools
我们内部 Asana 工具的保留测试集性能
Analyzing results(分析结果)
Agents are your helpful partners in spotting issues and providing feedback on everything from contradictory tool descriptions to inefficient tool implementations and confusing tool schemas. However, keep in mind that what agents omit in their feedback and responses can often be more important than what they include. LLMs don’t always say what they mean.
智能体是你在发现问题和提供反馈方面的得力助手,无论是工具描述自相矛盾、工具实现效率低下,还是工具结构令人困惑。但请记住,智能体在反馈和回答中省略的内容往往比其包含的内容更重要——大语言模型(LLM)并不总是言其所指。
Observe where your agents get stumped or confused. Read through your evaluation agents’ reasoning and feedback (or CoT) to identify rough edges. Review the raw transcripts (including tool calls and tool responses) to catch any behavior not explicitly described in the agent’s CoT. Read between the lines; remember that your evaluation agents don’t necessarily know the correct answers and strategies.
观察你的智能体在哪些地方卡住或感到困惑。仔细阅读评估智能体的推理过程与反馈(或思维链 CoT),以识别工具中的粗糙边缘。同时,审阅原始交互记录(包括工具调用和工具响应),捕捉那些未在智能体 CoT 中明确描述的行为。学会“读字里行间”;要记住,你的评估智能体未必知道正确的答案或策略。
Analyze your tool calling metrics. Lots of redundant tool calls might suggest some rightsizing of pagination or token limit parameters is warranted; lots of tool errors for invalid parameters might suggest tools could use clearer descriptions or better examples. When we launched Claude’s web search tool, we identified that Claude was needlessly appending 2025 to the tool’s query parameter, biasing search results and degrading performance (we steered Claude in the right direction by improving the tool description).
分析你的工具调用指标。大量冗余的工具调用可能表明需要调整分页或 token 限制参数;而大量因参数无效导致的工具错误,则可能说明工具描述不够清晰或缺乏有效示例。例如,在推出 Claude 的网页搜索工具时,我们发现它会无谓地在查询参数末尾附加“2025”,从而偏置搜索结果并降低性能——我们通过改进工具描述成功引导 Claude 走向正确方向。
Collaborating with agents(与智能体协作)
You can even let agents analyze your results and improve your tools for you. Simply concatenate the transcripts from your evaluation agents and paste them into Claude Code. Claude is an expert at analyzing transcripts and refactoring lots of tools all at once—for example, to ensure tool implementations and descriptions remain self-consistent when new changes are made.
你甚至可以让智能体为你分析结果并自动改进工具。只需将评估智能体的交互记录拼接起来,粘贴到 Claude Code 中即可。Claude 擅长分析交互日志,并能一次性重构大量工具——例如,确保在引入新变更后,工具的实现与描述仍保持自洽。
In fact, most of the advice in this post came from repeatedly optimizing our internal tool implementations with Claude Code. Our evaluations were created on top of our internal workspace, mirroring the complexity of our internal workflows, including real projects, documents, and messages.
事实上,本文中的大部分建议都源于我们反复使用 Claude Code 优化内部工具实现的经验。我们的评估基于内部工作空间构建,真实复现了内部工作流的复杂性,包括真实的项目、文档和消息。
We relied on held-out test sets to ensure we did not overfit to our “training” evaluations. These test sets revealed that we could extract additional performance improvements even beyond what we achieved with "expert" tool implementations—whether those tools were manually written by our researchers or generated by Claude itself.
我们依赖保留测试集来确保不会对“训练”评估产生过拟合。这些测试集揭示:即使在已有“专家级”工具实现(无论是研究人员手动编写还是由 Claude 自动生成)的基础上,我们仍能进一步挖掘出额外的性能提升。
In the next section, we’ll share some of what we learned from this process.
在下一节中,我们将分享从这一过程中获得的一些关键经验。
Principles for writing effective tools(编写高效工具的原则)
In this section, we distill our learnings into a few guiding principles for writing effective tools.
本节将我们的经验提炼为几条编写高效工具的核心原则。
Choosing the right tools for agents(为智能体选择合适的工具)
More tools don’t always lead to better outcomes. A common error we’ve observed is tools that merely wrap existing software functionality or API endpoints—whether or not the tools are appropriate for agents. This is because agents have distinct “affordances” to traditional software—that is, they have different ways of perceiving the potential actions they can take with those tools
更多工具并不总能带来更好结果。我们常观察到的一个错误是:简单包装现有软件功能或 API 端点的工具——无论这些工具是否真正适合智能体使用。这是因为智能体与传统软件具有不同的“可供性”(affordances),即它们感知自身可执行操作的方式存在本质差异。
LLM agents have limited "context" (that is, there are limits to how much information they can process at once), whereas computer memory is cheap and abundant. Consider the task of searching for a contact in an address book. Traditional software programs can efficiently store and process a list of contacts one at a time, checking each one before moving on.
大语言模型智能体的“上下文”容量有限(即一次能处理的信息量受限),而计算机内存则廉价且充裕。以在通讯录中查找联系人为例:传统软件可以高效地逐个存储和处理联系人列表,在检查完一个后再处理下一个。
However, if an LLM agent uses a tool that returns ALL contacts and then has to read through each one token-by-token, it's wasting its limited context space on irrelevant information (imagine searching for a contact in your address book by reading each page from top-to-bottom—that is, via brute-force search). The better and more natural approach (for agents and humans alike) is to skip to the relevant page first (perhaps finding it alphabetically).
然而,如果 LLM 智能体使用一个返回全部联系人的工具,然后不得不逐个 token 地阅读每个联系人,就会把宝贵的上下文空间浪费在无关信息上(想象你在通讯录中一页一页从头读到尾来查找某人——这相当于暴力搜索)。对智能体和人类而言,更优、更自然的做法是先跳转到相关页面(比如按字母顺序定位)。
We recommend building a few thoughtful tools targeting specific high-impact workflows, which match your evaluation tasks and scaling up from there. In the address book case, you might choose to implement a search_contacts or message_contact tool instead of a list_contacts tool.
我们建议先构建少量经过深思熟虑的工具,聚焦于特定高影响力的工作流,并确保这些工具与你的评估任务匹配,再逐步扩展。在通讯录场景中,你应考虑实现 search_contacts 或 message_contact 工具,而非 list_contacts 工具。
Tools can consolidate functionality, handling potentially multiple discrete operations (or API calls) under the hood. For example, tools can enrich tool responses with related metadata or handle frequently chained, multi-step tasks in a single tool call.
工具可在内部整合多项功能,将多个离散操作(或 API 调用)封装于单一工具调用之中。例如,工具可以在响应中补充相关元数据,或将频繁串联的多步骤任务合并为一次调用。
Here are some examples:
Instead of implementing a list_users, list_events, and create_event tools, consider implementing a schedule_event tool which finds availability and schedules an event.
Instead of implementing a read_logs tool, consider implementing a search_logs tool which only returns relevant log lines and some surrounding context.
Instead of implementing get_customer_by_id, list_transactions, and list_notes tools, implement a get_customer_context tool which compiles all of a customer’s recent & relevant information all at once.
以下是一些示例:
与其分别实现 list_users、list_events 和 create_event 工具,不如实现一个 schedule_event 工具,它能自动查找空闲时间并安排会议。
与其实现 read_logs 工具,不如实现 search_logs 工具,仅返回相关的日志行及其上下文。
与其分别实现 get_customer_by_id、list_transactions 和 list_notes 工具,不如实现一个 get_customer_context 工具,一次性汇总客户所有近期且相关的信息。
Make sure each tool you build has a clear, distinct purpose. Tools should enable agents to subdivide and solve tasks in much the same way that a human would, given access to the same underlying resources, and simultaneously reduce the context that would have otherwise been consumed by intermediate outputs.
确保你构建的每个工具都有清晰、明确的用途。工具应使智能体能够像人类一样(在拥有相同底层资源的前提下)拆解并解决任务,同时减少中间输出所消耗的上下文空间。
Too many tools or overlapping tools can also distract agents from pursuing efficient strategies. Careful, selective planning of the tools you build (or don’t build) can really pay off.
过多或功能重叠的工具也会分散智能体注意力,使其偏离高效策略。因此,对你构建(或不构建)哪些工具进行审慎、有选择性的规划,将带来显著回报。
Namespacing your tools(为工具设置命名空间)
Your AI agents will potentially gain access to dozens of MCP servers and hundreds of different tools–including those by other developers. When tools overlap in function or have a vague purpose, agents can get confused about which ones to use.
你的 AI 智能体可能会访问数十个 MCP 服务器和数百种不同工具——其中还包括其他开发者提供的工具。当工具功能重叠或目的模糊时,智能体容易混淆该使用哪一个。
Namespacing (grouping related tools under common prefixes) can help delineate boundaries between lots of tools; MCP clients sometimes do this by default. For example, namespacing tools by service (e.g., asana_search, jira_search) and by resource (e.g., asana_projects_search, asana_users_search), can help agents select the right tools at the right time.
命名空间(即将相关工具归入共同前缀下)有助于在大量工具之间划定清晰边界;某些 MCP 客户端默认会这样做。例如,按服务命名(如 asana_search、jira_search)或按资源类型命名(如 asana_projects_search、asana_users_search),可帮助智能体在恰当时机选用正确的工具。
We have found selecting between prefix- and suffix-based namespacing to have non-trivial effects on our tool-use evaluations. Effects vary by LLM and we encourage you to choose a naming scheme according to your own evaluations.
我们发现,采用前缀式还是后缀式命名空间会对工具使用评估产生不可忽视的影响。这种影响因 LLM 而异,因此我们建议你根据自己的评估结果选择合适的命名方案。
Agents might call the wrong tools, call the right tools with the wrong parameters, call too few tools, or process tool responses incorrectly. By selectively implementing tools whose names reflect natural subdivisions of tasks, you simultaneously reduce the number of tools and tool descriptions loaded into the agent’s context and offload agentic computation from the agent’s context back into the tool calls themselves. This reduces an agent’s overall risk of making mistakes.
智能体可能会调用错误的工具、用错参数调用正确工具、调用工具数量不足,或错误处理工具响应。通过有选择地实现那些名称能反映任务自然划分的工具,你不仅能减少加载到智能体上下文中的工具数量和描述文本,还能将部分智能体计算负载从上下文转移到工具调用本身,从而整体降低智能体犯错的风险。
Returning meaningful context from your tools(让工具返回有意义的上下文)
In the same vein, tool implementations should take care to return only high signal information back to agents. They should prioritize contextual relevance over flexibility, and eschew low-level technical identifiers (for example: uuid, 256px_image_url, mime_type). Fields like name, image_url, and file_type are much more likely to directly inform agents’ downstream actions and responses.
同理,工具实现应谨慎确保仅向智能体返回高信号价值的信息。应优先考虑上下文相关性而非灵活性,并避免返回低层级的技术标识符(例如:uuid、256px_image_url、mime_type)。像 name、image_url 和 file_type 这类字段更可能直接指导智能体的后续操作和响应。
Agents also tend to grapple with natural language names, terms, or identifiers significantly more successfully than they do with cryptic identifiers. We’ve found that merely resolving arbitrary alphanumeric UUIDs to more semantically meaningful and interpretable language (or even a 0-indexed ID scheme) significantly improves Claude’s precision in retrieval tasks by reducing hallucinations.
此外,智能体在处理自然语言名称、术语或标识符时,通常比处理晦涩的技术 ID 表现好得多。我们发现,仅将任意字母数字组成的 UUID 替换为语义更明确、可解释性更强的表述(甚至简单的 0 起始索引 ID 方案),就能显著提升 Claude 在检索任务中的准确率,并减少幻觉。
In some instances, agents may require the flexibility to interact with both natural language and technical identifiers outputs, if only to trigger downstream tool calls (for example, search_user(name=’jane’) → send_message(id=12345)). You can enable both by exposing a simple response_format enum parameter in your tool, allowing your agent to control whether tools return “concise” or “detailed” responses (images below).
在某些情况下,智能体可能需要同时与自然语言和技术标识符交互(哪怕只是为了触发下游工具调用,例如:search_user(name='jane') → send_message(id=12345))。你可通过在工具中暴露一个简单的 response_format 枚举参数来支持这两种模式,让智能体自行控制工具返回“简洁”还是“详细”的响应(见下图)。
You can add more formats for even greater flexibility, similar to GraphQL where you can choose exactly which pieces of information you want to receive. Here is an example ResponseFormat enum to control tool response verbosity:
你还可以增加更多格式以获得更高灵活性,类似于 GraphQL,允许精确指定希望接收的信息片段。以下是一个用于控制工具响应详略程度的 ResponseFormat 枚举示例:
enum ResponseFormat {
DETAILED = "detailed",
CONCISE = "concise"
}Here’s an example of a detailed tool response (206 tokens):
以下是一个详细工具响应的示例(共 206 个 token):
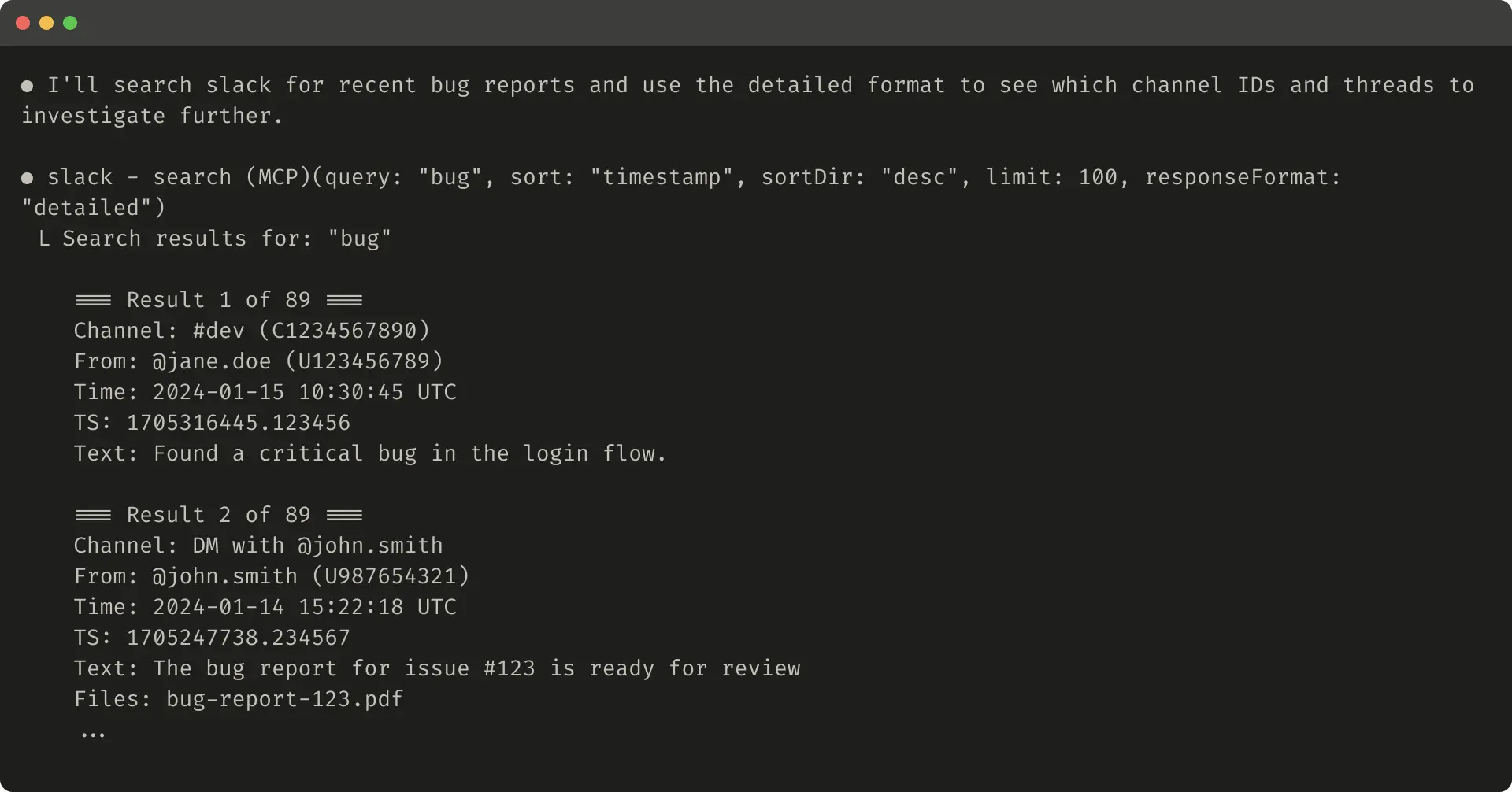
Here’s an example of a concise tool response (72 tokens):
以下是一个简洁工具响应的示例(72 个 token):
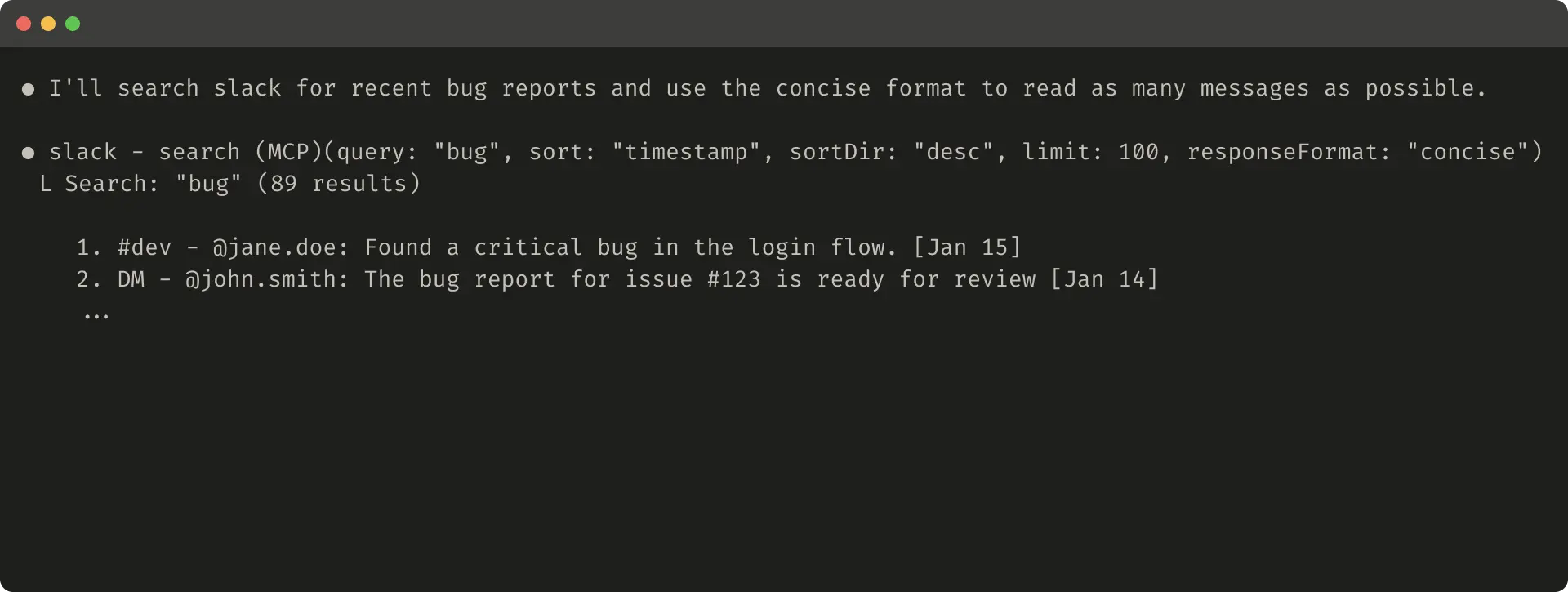
Slack threads and thread replies are identified by unique thread_ts which are required to fetch thread replies. thread_ts and other IDs (channel_id, user_id) can be retrieved from a “detailed” tool response to enable further tool calls that require these. “concise” tool responses return only thread content and exclude IDs. In this example, we use ~⅓ of the tokens with “concise” tool responses.
Slack 的主题帖和回复通过唯一的 thread_ts 标识,获取回复内容必须提供该标识。thread_ts 及其他 ID(如 channel_id、user_id)可从“详细”工具响应中获取,以便后续需要这些参数的工具调用。“简洁”工具响应仅返回主题内容,不包含任何 ID。在此示例中,使用“简洁”响应仅消耗了约三分之一的 token。
Even your tool response structure—for example XML, JSON, or Markdown—can have an impact on evaluation performance: there is no one-size-fits-all solution. This is because LLMs are trained on next-token prediction and tend to perform better with formats that match their training data. The optimal response structure will vary widely by task and agent. We encourage you to select the best response structure based on your own evaluation.
即便是工具响应的结构格式——例如 XML、JSON 或 Markdown——也可能影响评估性能:并不存在放之四海而皆准的解决方案。这是因为大语言模型基于下一 token 预测进行训练,对与其训练数据风格匹配的格式表现更佳。最优的响应结构会因任务和智能体的不同而差异显著。我们建议你根据自己的评估结果选择最合适的响应结构。
Optimizing tool responses for token efficiency(优化工具响应以提升 token 效率)
Optimizing the quality of context is important. But so is optimizing the quantity of context returned back to agents in tool responses.
优化上下文的质量固然重要,但同样关键的是优化工具响应返回给智能体的上下文数量。
We suggest implementing some combination of pagination, range selection, filtering, and/or truncation with sensible default parameter values for any tool responses that could use up lots of context. For Claude Code, we restrict tool responses to 25,000 tokens by default. We expect the effective context length of agents to grow over time, but the need for context-efficient tools to remain.
我们建议对可能占用大量上下文的工具响应,结合使用分页、范围选择、过滤和/或截断机制,并设置合理的默认参数值。对于 Claude Code,默认情况下我们将工具响应限制在 25,000 个 token 以内。尽管我们预计未来智能体的有效上下文长度将持续增长,但对上下文高效工具的需求仍将长期存在。
If you choose to truncate responses, be sure to steer agents with helpful instructions. You can directly encourage agents to pursue more token-efficient strategies, like making many small and targeted searches instead of a single, broad search for a knowledge retrieval task. Similarly, if a tool call raises an error (for example, during input validation), you can prompt-engineer your error responses to clearly communicate specific and actionable improvements, rather than opaque error codes or tracebacks.
如果你选择对响应进行截断,请务必通过清晰的说明引导智能体。你可以直接鼓励智能体采用更节省 token 的策略,例如在知识检索任务中执行多次小范围、精准的搜索,而非单次宽泛的搜索。同样,如果工具调用触发错误(例如输入验证失败),应通过提示工程设计错误响应,明确传达具体且可操作的改进建议,而非返回晦涩的错误代码或堆栈追踪信息。
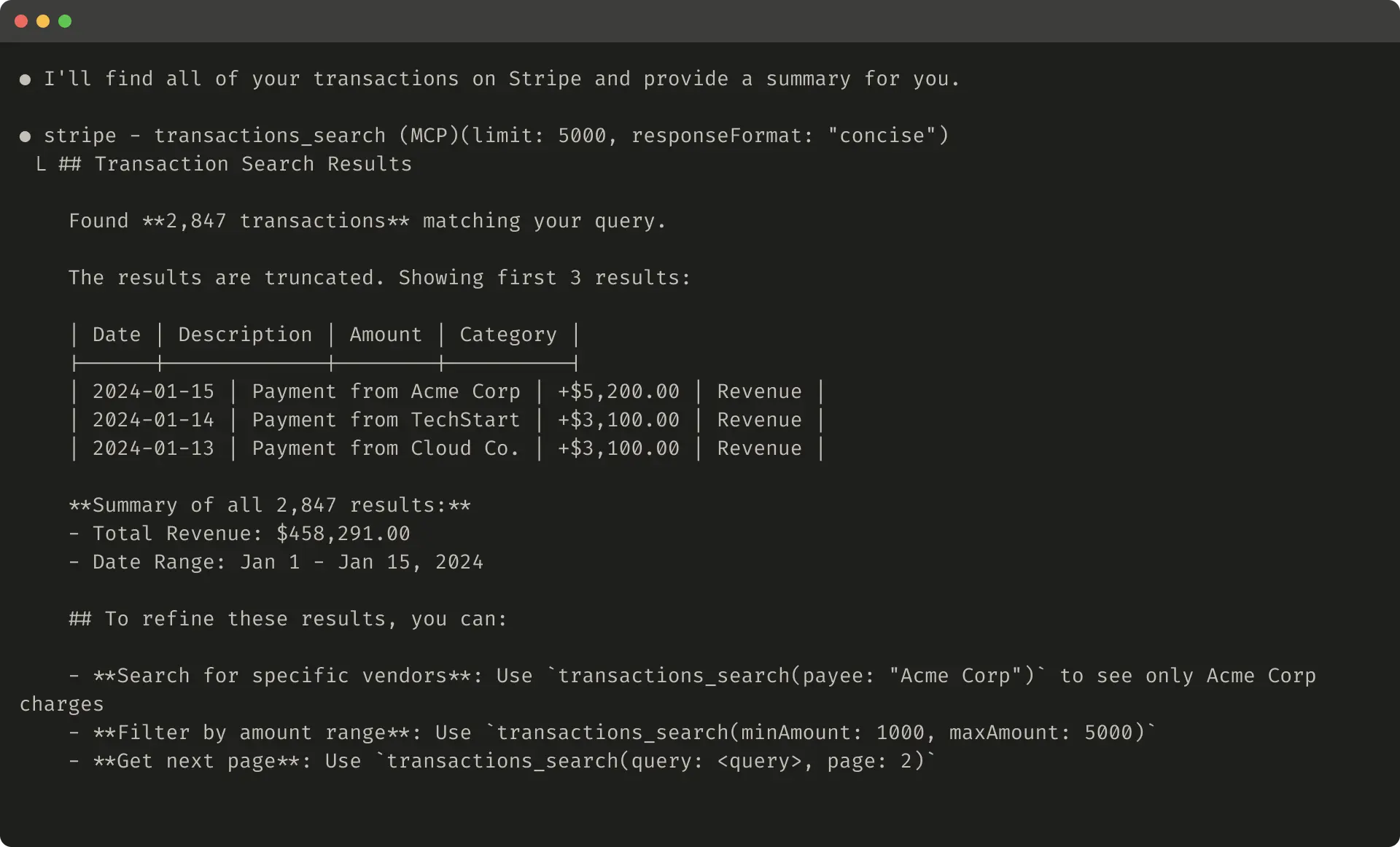
Here’s an example of a truncated tool response:
以下是一个截断式工具响应的示例:
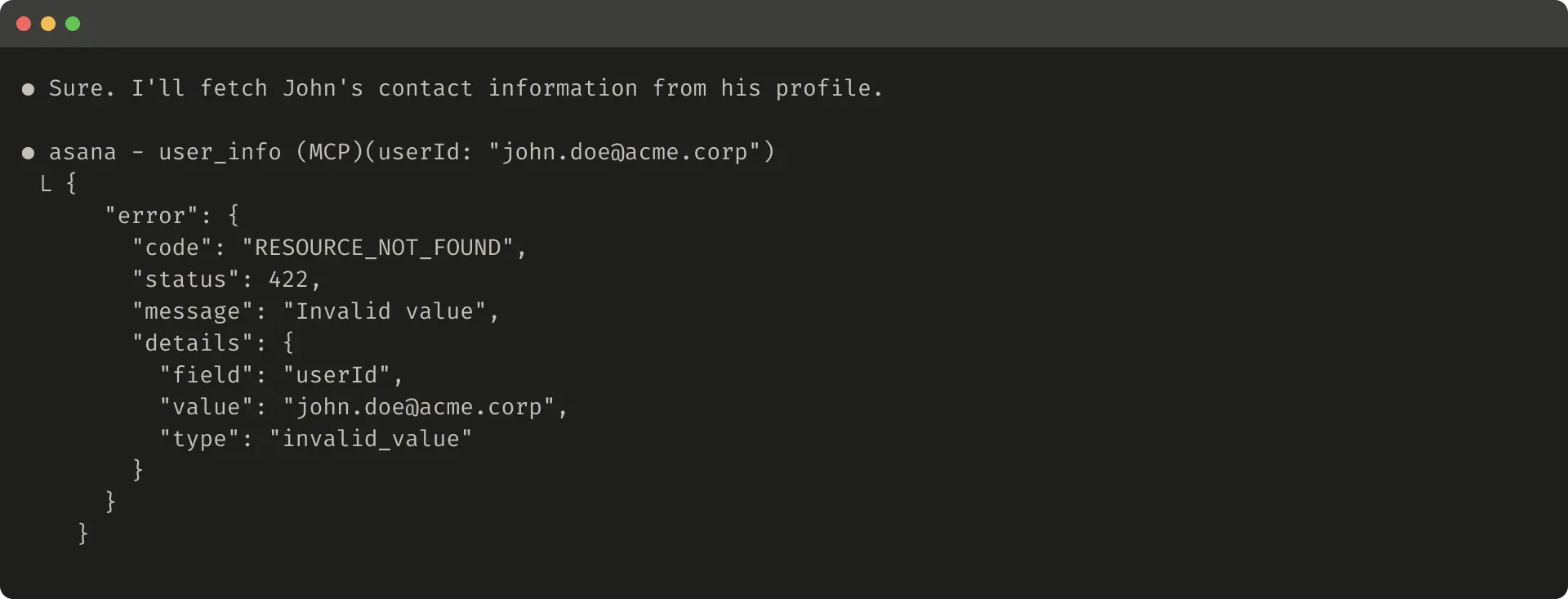
Here’s an example of an unhelpful error response:
以下是一个无帮助的错误响应示例:
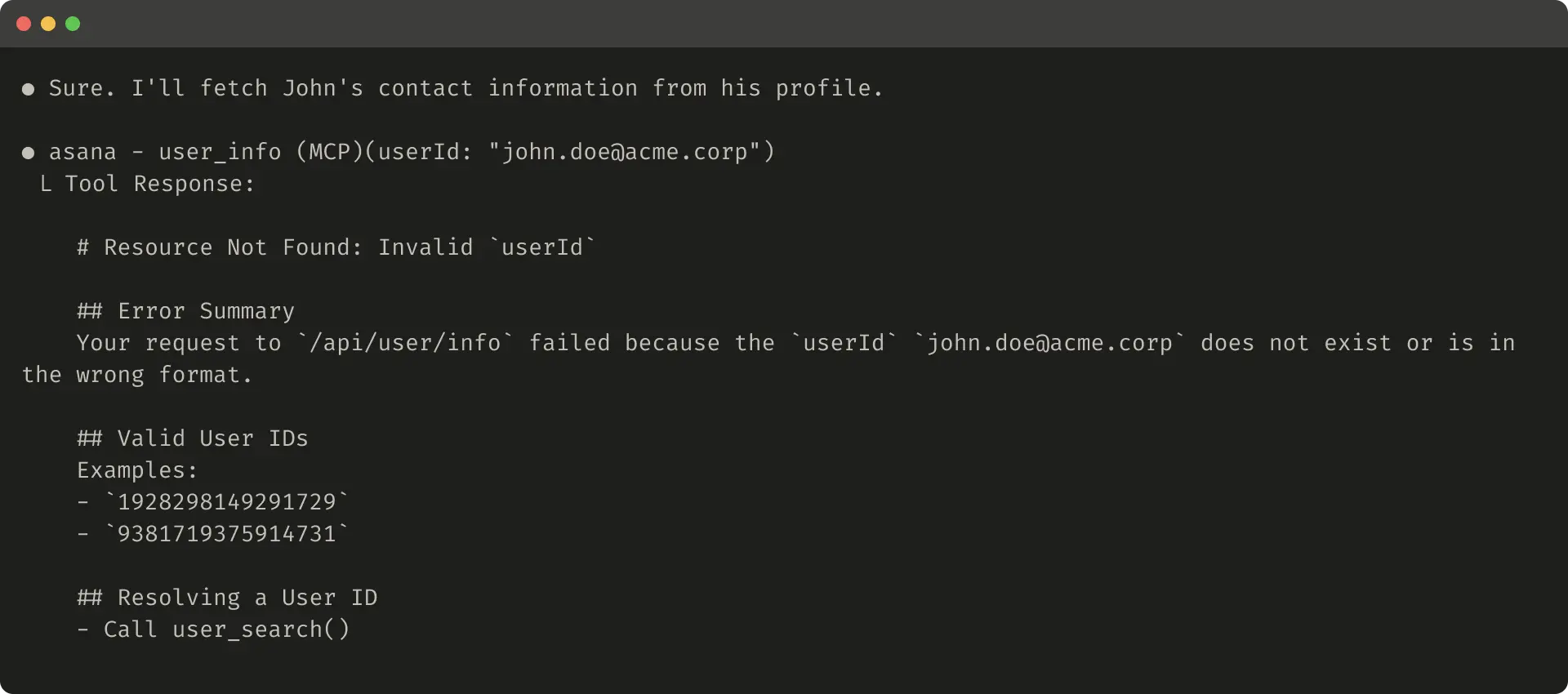
Here’s an example of a helpful error response:
以下是一个有帮助的错误响应示例:
Tool truncation and error responses can steer agents towards more token-efficient tool-use behaviors (using filters or pagination) or give examples of correctly formatted tool inputs.
工具截断和错误响应可以引导智能体采用更节省 token 的工具使用行为(例如使用过滤或分页),或提供正确格式化工具输入的示例。
Prompt-engineering your tool descriptions(对工具描述进行提示工程优化)
We now come to one of the most effective methods for improving tools: prompt-engineering your tool descriptions and specs. Because these are loaded into your agents’ context, they can collectively steer agents toward effective tool-calling behaviors.
现在我们来到提升工具效果最有效的方法之一:对工具描述和规范进行提示工程(prompt engineering)优化。由于这些内容会被加载到智能体的上下文中,它们能够共同引导智能体形成高效的工具调用行为。
When writing tool descriptions and specs, think of how you would describe your tool to a new hire on your team. Consider the context that you might implicitly bring—specialized query formats, definitions of niche terminology, relationships between underlying resources—and make it explicit. Avoid ambiguity by clearly describing (and enforcing with strict data models) expected inputs and outputs. In particular, input parameters should be unambiguously named: instead of a parameter named user, try a parameter named user_id.
在编写工具描述和规范时,请设想你正在向团队中的一位新成员解释该工具。思考你可能默认具备但未明说的上下文——例如特定的查询格式、专业术语的定义、底层资源之间的关系——并将其明确写出来。通过清晰描述(并借助严格的数据模型加以约束)预期的输入和输出,避免歧义。尤其要注意输入参数的命名应明确无误:与其使用名为 user 的参数,不如使用 user_id。
With your evaluation you can measure the impact of your prompt engineering with greater confidence. Even small refinements to tool descriptions can yield dramatic improvements. Claude Sonnet 3.5 achieved state-of-the-art performance on the SWE-bench Verified evaluation after we made precise refinements to tool descriptions, dramatically reducing error rates and improving task completion.
借助你的评估体系,你可以更有信心地衡量提示工程优化带来的实际影响。即便是对工具描述进行微小调整,也可能带来显著的性能提升。例如,在我们对工具描述进行精确优化后,Claude Sonnet 3.5 在 SWE-bench Verified 评估中达到了业界领先水平,错误率大幅降低,任务完成率显著提高。
You can find other best practices for tool definitions in our Developer Guide. If you’re building tools for Claude, we also recommend reading about how tools are dynamically loaded into Claude’s system prompt. Lastly, if you’re writing tools for an MCP server, tool annotations help disclose which tools require open-world access or make destructive changes.
你可以在我们的《开发者指南》中找到更多关于工具定义的最佳实践。如果你正在为 Claude 构建工具,我们也建议阅读有关工具如何动态加载到 Claude 系统提示中的说明。此外,如果你在编写 MCP 服务器的工具,工具注解(tool annotations)有助于标明哪些工具需要开放世界访问权限,或会执行破坏性操作。
Looking ahead(展望未来)
To build effective tools for agents, we need to re-orient our software development practices from predictable, deterministic patterns to non-deterministic ones.
要为智能体构建高效工具,我们需要将软件开发实践从可预测、确定性的模式转向非确定性的范式。
Through the iterative, evaluation-driven process we’ve described in this post, we've identified consistent patterns in what makes tools successful: Effective tools are intentionally and clearly defined, use agent context judiciously, can be combined together in diverse workflows, and enable agents to intuitively solve real-world tasks.
通过本文所述的迭代式、以评估驱动的流程,我们已识别出决定工具成功的一致性模式:高效的工具具有明确且有意的设计,能审慎使用智能体的上下文资源,可在多样化的流程中灵活组合,并使智能体能够直观地解决现实世界任务。
In the future, we expect the specific mechanisms through which agents interact with the world to evolve—from updates to the MCP protocol to upgrades to the underlying LLMs themselves. With a systematic, evaluation-driven approach to improving tools for agents, we can ensure that as agents become more capable, the tools they use will evolve alongside them.
未来,我们预计智能体与世界交互的具体机制将持续演进——无论是 MCP 协议的更新,还是底层大语言模型本身的升级。只要采用系统化、以评估驱动的方法持续改进工具,就能确保随着智能体能力的提升,其所使用的工具也能同步进化。
Acknowledgements(致谢)
Written by Ken Aizawa with valuable contributions from colleagues across Research (Barry Zhang, Zachary Witten, Daniel Jiang, Sami Al-Sheikh, Matt Bell, Maggie Vo), MCP (Theodora Chu, John Welsh, David Soria Parra, Adam Jones), Product Engineering (Santiago Seira), Marketing (Molly Vorwerck), Design (Drew Roper), and Applied AI (Christian Ryan, Alexander Bricken).
本文由 Ken Aizawa 撰写,并得到了来自多个团队同事的宝贵贡献:研究团队(Barry Zhang、Zachary Witten、Daniel Jiang、Sami Al-Sheikh、Matt Bell、Maggie Vo)、MCP 团队(Theodora Chu、John Welsh、David Soria Parra、Adam Jones)、产品工程团队(Santiago Seira)、市场团队(Molly Vorwerck)、设计团队(Drew Roper)以及应用 AI 团队(Christian Ryan、Alexander Bricken)。

发表评论 取消回复